This is a crosspost from VanessaSaurus, dinosaurs, programming, and parsnips. See the original post here.
For many years, there has been a battle between cloud and HPC. The cloud side of the equation says “micro services, cloud native!” and the HPC side says “too expensive!” Conversations often don’t progress because both sides are up-in-arms and focused on why they cannot work together. At best, we might get access to cloud from an HPC center, or an company might present a product as branded for “HPC.” But it’s not truly collaborative in the way that I’d like.
I’ll also step back and comment that (I do not believe) folks (myself included) on the HPC side have done enough to sit at the table. For example, we haven’t been a voice in the Open Containers Initiative (although I’ve tried), nor have we been present (historically) for conferences that are more focused around cloud native technologies. There is no pointing fingers or fault here - it’s just a matter of two different cultures, and it’s been challenging figuring out how to talk to one another, and how to work together. I’ve tried my best to be involved, to the best of my ability, in small ways on both sides. But I’m only one person. This isn’t to say there haven’t been small collaborations, but I believe we can do more.
Change is Coming
I think this is going to change. The reason is because both sides of the equation have started to realize we have similar goals, and it’s not about creating hybrid environments – having both pancakes and waffles for breakfast – but rather convergence – recognizing that pancakes and waffles are both kinds of breakfast cakes, and we can take features that we like of each to create a breakfast cake that will make everyone happy. The idea of “Converged Computing” comes from my amazing team (see Dan’s talk at KubeCon here) and is the idea that technologies from HPC can be integrated into more traditionally cloud approaches to produce a solution that solves problems on both sides. Explicitly for these projects, it means testing the Flux Framework scheduler alongside Kubernetes. Do we still want portable workflows that can move from an HPC environment to cloud? Of course. However, the niche or gradient that I’m interested in is the space that lives between these two worlds.
While I won’t go into huge detail (this would be more appropriate for a talk) the lab openly works on Flux Framework, a resource manager that (in my opinion) is one of the coolest projects coming out of our space. I started working with these teams a few months ago, and am bringing my excitement and vision for (what I hope to be) a future where we are actively developing alongside other Kubernetes projects, and our work is well-known and established in this space. What does that mean? Let me share some cool work under development. This is all being done publicly on GitHub, so there is no issue to talk about it! My first year or so at the lab I was hired under a research project, and although I learned a lot, I haven’t felt inspired and driven until starting this work. Let’s talk about some of it! 🎉️
The Flux Operator

If you aren’t familiar with Kubernetes Operators, let’s step back and talk about a human operator. If you are a syadmin managing apps with associated services and databases on a cluster, you often had to do maintenance or update tasks like increasing a storage volume, or modifying a service to a new user need. As this pattern has emerged as a common thing, they have come up with the concept of a Kubernetes Operator - an actual controller you install to your cluster that can automate this. In simple terms, after you install an operator to your cluster, you can hand it a desired state (represented in a yaml configuration file) and the operator will do whatever it takes to reach that state. What does that means in the context of Flux? The Flux Operator is interested in creating what we are calling a “Mini Cluster,” illustrated below.
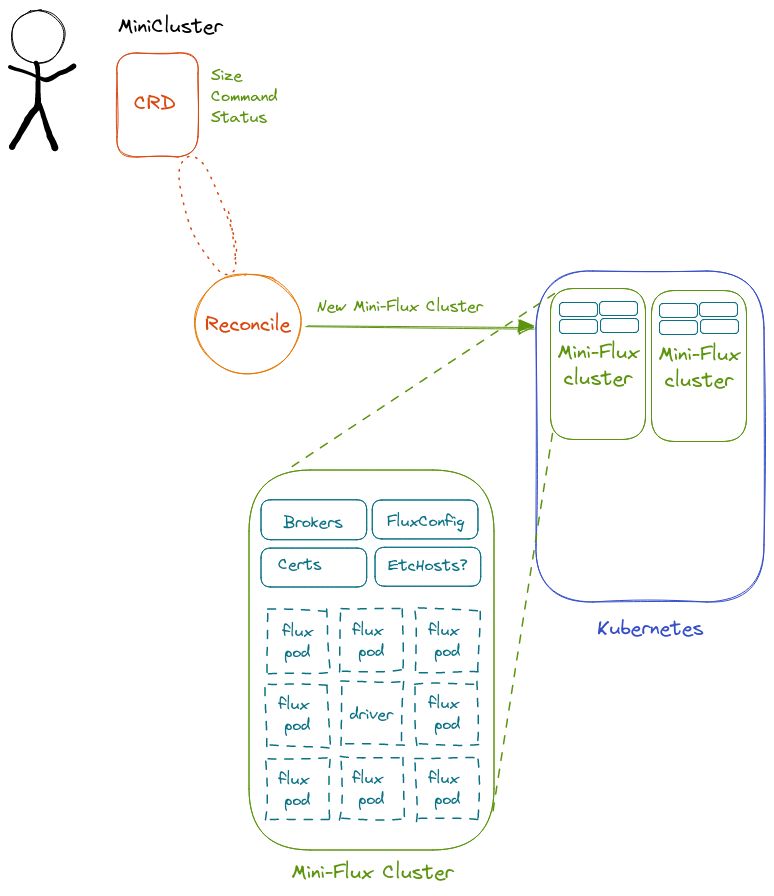
In Kubernetes object terms this is an Indexed Job, a few config maps, secrets, and a RESTFul API and user interface that I designed exposed as a service. You can read more about our current design here.
This Mini Cluster is generated from a “custom resource definition” or CRD (the yaml you provide), and it can take these parameters. Concetually, you as the user own the Mini Cluster and can submit jobs to it (either via the web interface or the API) until you are done. When you are done, you can bring down the cluster.
We are excited for this work because in the next months (to a bit longer) we are going to be testing different kinds of workloads running using Flux alongside this Mini Cluster, but on Kubernetes! I’ve started a small repository of dummy examples that I’m extending quickly at rse-ops/flux-hpc and please open an issue there if you have a suggestion.
Stay Tuned!
Stay tuned for more work in this space! I’ve been doing a ton of programming in Go, Python, and working on a wide range of technologies, and fairly quickly, and I am very much in my happy place. Please come and join us! ❤️