This is a crosspost from VanessaSaurus, dinosaurs, programming, and parsnips. See the original post here.
Documentation is not remotely sexy. And according to the Journal of Open Source Software, if you invest time and thought into a version controlled documentation server that could serve researchers in so many ways, it is not research software.
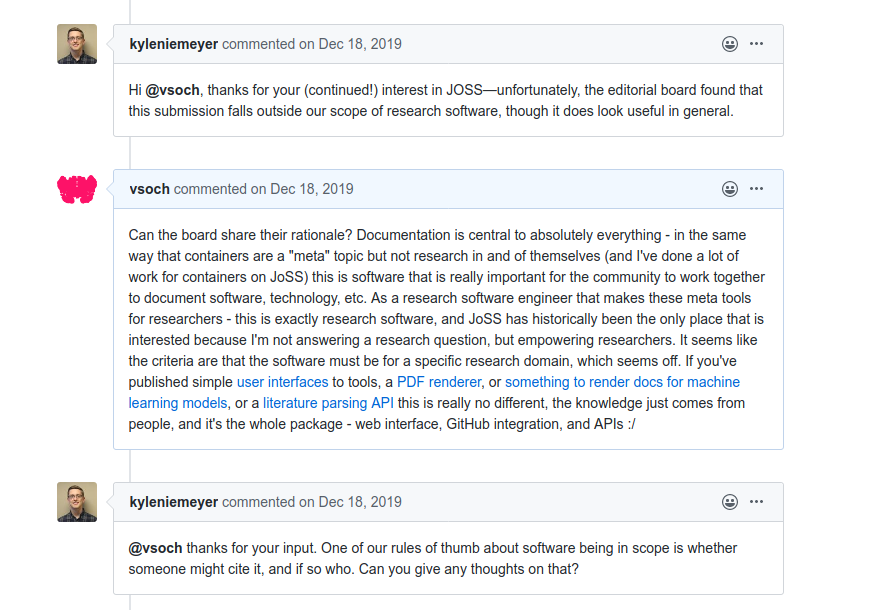
I tried to give the many examples (other than providing documentation for researchers, or a place for a center or group to collborate on documentation) of ways that it could actually be used to help with research. Having automation and an API for programmatic access to data is pretty useful, if you ask me:
But as you can see, it was rejected. I was really heart broken. It wasn’t just because I had worked for weeks on a project that I was passionate about, it was because I truly believed it could be useful. It was because someone else was telling me that something I knew to be research software was not research software. I want to talk about this a bit. If you don’t want to read, then I’ll give the summary of my story - we need to advocate for our work and seek out review when other’s won’t help us, and for that reason I’ve published the paper on ArXiv. I am so grateful to this platform for giving my software a voice.
What is research software?
According to the conversation I had with JoSS, research software must be citable.
One of our rules of thumb about software being in scope is whether someone might cite it, and if so who.
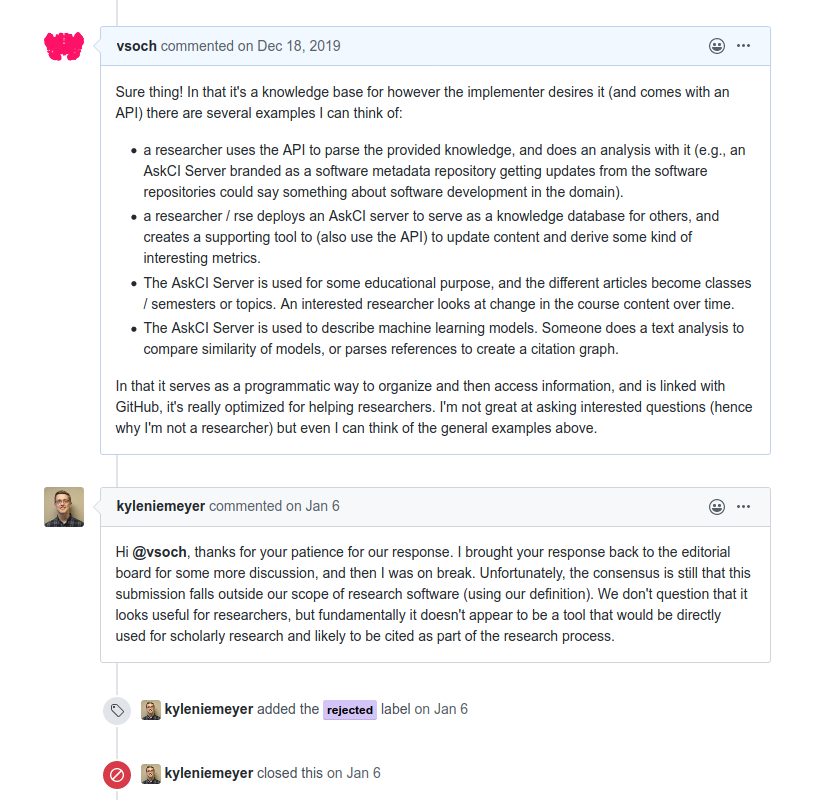
Under this definition, a tool that serves as a data API for almost any kind of data (that is version controlled) would be citable. So that couldn’t have been the whole story, because it was rejected. The reviewer added more later, after meeting with his secret panel of experts:
I brought your response back to the editorial board for some more discussion, and then I was on break. Unfortunately, the consensus is still that this submission falls outside our scope of research software (using our definition). We don’t question that it looks useful for researchers, but fundamentally it doesn’t appear to be a tool that would be directly used for scholarly research and likely to be cited as part of the research process.
The part that hit me was that software worthy of this label would be directly used for scholarly research. That implicitly says to me that any kind of work that isn’t directly answering some domain-specific research question “scholarly” is not research software. That implicitly says to me that the only way I can publish to support my own career or get the attention of my users, the academic community, is to bootstrap on someone else’s scholarly work. That implicitly says to me that there is really no existing avenue for a research software engineer to publish research software unless it fits in the mold of domain research. But… containers? workflow managers? GNU utils? Git? And what about the inordinate numbers of tools that are out there that indirectly are a game changers for the same scholarly research?
My strong inclination is that the majority of folks on this panel think about research software as data science tools. If I look across the JoSS, this is the kind of work that I intend to see - R, Python, and containers intended for directly doing data science. It’s not to say that these are not research software, but as more of a generalist developer, I see this definition extremely limiting. I should be able to write software that goes against the grain (e.g., I’m unlikely to get grant money for a documentation server that is beat out by much sexier sounding projects, if I could even apply for grants) that I know to be useful for researchers, and be able to publish it. I’m hugely troubled that the “Journal of Open Source Software” is not really supporting open source developers that are developing software for research. It’s supporting researchers and data scientists that open source their tools. These two things are different. If I defined research software, and scoped for the Journal of Open Source software, I’d say that it’s open source software developed with the sole intention to directly or indirectly improve the practices of research.
What are the cultural implications?
What JoSS doesn’t realize is that it hurts the overall community to not support research software engineers and their work. It hurts just enough to make me less likely to work on a tool that I think is important, because whether we like it or not, publication is still the best way to get researcher attention for feedback and usage. It means that, over time, small groups of people in power (the committee at JoSS) get to make decisions for us about what defines research software. It’s really no different than people in positions of power presenting a very narrow definition of research software engineer. If you aren’t upset about this, you should be.
What can we do?
You can’t argue with someone in a higher place than you about what you believe if they make the choices, and you’ve been rejected. I reached out to several other journals, and despite each taking upwards of many hours to redo LaTex formatting, it was rejections all around. The culture is not set up or ready to support generalist open source software projects that aren’t aimed at data science directly, but might provide an infrastructure to improve the practice or metadata behind some kind of research.
I’d like to hear others’ thoughts on what is research software, if you’ve been in a situation like mine, and if so, what can be done. With no choices left, I’ve decided to write this post and publish my work on ArXiv where it will likely be forgotten. But that’s better than nothing because I have more pressing things to work on than trying to convince some small panel that my work is worthy. The greatest success here is, when you believe in something, continuing to advocate for your work even when others will not. I believe that we can do better to support research software engineers, and their work.