This is a crosspost from VanessaSaurus, dinosaurs, programming, and parsnips. See the original post here.
I stumbled on a little bit of magic last night. Specifically, it was the repository associated with this paper that used a clever algorithm to match a picture (such as a face) to a video (such as a person talking) to generate a new video. You can then pair the audio with the new video, and like magic, you have a talking painting, different person, or even an inanimate object with a face. As you might imagine, I went to town and made a ton of videos, and could barely contain my excitement to share this with you! Here is one of my favorite:
Clone the repository
If you are planning to run things locally (and install dependencies) you’ll need to clone the repository, and do that. Note that I’ll show instructions later for using a container. I found a bug with using ffmpeg on my local machine, so I’ll direct you to use the branch from my fork.
git clone -b fix/ffmpeg-frames-bug https://github.com/researchapps/first-order-model
cd first-order-model
mkdir -p driving videos img
For each of the folders above, we will put driving videos in driving, output videos in videos (both those without sound and finished with it) and input images in img. To install dependencies, after you have your Python environment of choice active:
pip install -r requirements.txt
And then proceed to generate a video for your first shot! After I got this up and running for the first time, it was pure joy!
I wound up building a container, and it was actually very unlike me to run something on my local machine. Either way, the model checkpoints are downlaoded from here.
Generating a Video
The first thing you need to do is to generate videos to match to. Ideally these should be 256 by 256, and I’d suggest a good starting size is no longer than 40 seconds. On a CPU this size video will take anywhere between 10 to 20 minutes to be produced. The repository provides a script to resize a video for you (or actually to generate an ffmpeg command that you can run) but it didn’t work on my machine because I don’t have GPU, which is a dependency for the face alignment library. Instead, I found a very easy and free online converter where you generally want to:
- First reshape the canvas be square, e.g., take the smaller dimension, N, and make the image NXN
- Then resize the video to 256 by 256
- Convert to Mp4 and save
I saved these “template videos” to the “driving” folder. If you need to easily get them off of your phone, Google Photos uploads fairly quickly, and you can also send a file to yourself in Slack. I’m terrified to admit that I tried sending a rather embarassing video to myself, and I never found it. I suspect it’s floating out there somewhere in the internet universe. One additional note is that you shouldn’t worry too much about how you look, but focus on keeping your head fairly stable (some movement seems okay but not too much) and thinking about the movement of your eyes, eyebrows, and mouth.
Choosing a picture
This is where it gets fun, because you can literally choose any picture that has a mouth and eyes (and looks like a face). This might include paintings, other people, or stuffed animals or other inanimate objects. In practice I found that the pictures that worked the best had some kind of black or dark delineation between the lips, because the model seems to pick up on these and even add movement and teeth. If your mouth is not well defined (or if you have other lines in the image that are moving and could be mistaken for a mouth) it doesn’t come out as well as it would have. For all of these images that you choose, they should also be 256 by 256. I think you could change this by updating the config file, but it’s easier to just stick to the defaults.
It’s quite a bit of work editing / cropping all those videos, but it’s worth it! I used gimp, of course.
Running with GPU
While most of these I ran on my local machine (using a slow CPU) I wanted to test running with GPU, and so I logged into our cluster and briefly grabbed a GPU node to pull the container and try running a model. I wanted to make sure that if others used the container, that it would work with Singularity.
singularity pull docker://vanessa/first-order-model
mkdir -p videos
mkdir -p driving
We would then need a bunch of videos and images to use - in my case I had them on my local machine and used scp to get them onto my scratch space:
scp -r driving/ vsochat@login.sherlock.stanford.edu:/scratch/users/vsochat/first-order-model/videos
scp -r img/ vsochat@login.sherlock.stanford.edu:/scratch/users/vsochat/first-order-model/driving
The models and configuration files are provided in the container within the directory /app so I don’t need to worry about that. Since I’m running these interactively, I decided to test via an interactive shell.
singularity shell --nv first-order-model_latest.sif
cd /app
Your working directory with the videos and images should still be bound to where it was before (e.g., on my cluster we bind $HOME and $SCRATCH so I can reference files there. Let’s try running this with GPU! Remember this is relative to /app in the container.
/usr/bin/python3 demo.py --config config/vox-adv-256.yaml \
--driving_video $SCRATCH/first-order-model/driving/lesters-eggs.mp4 \
--source_image $SCRATCH/first-order-model/img/img/image17.png \
--checkpoint checkpoints/vox-adv-cpk.pth.tar \
--relative --adapt_scale \
--result_video $SCRATCH/first-order-model/videos/lesters-eggs-17-no-audio.mp4
important! If you have python modules installed to local that might conflict, you should either set the python no user site environment variable, or (if you are lazy like me) just delete them. When you finish up, you can then copy the finished (no audio) files back to your computer:
mkdir -p gpu-videos
scp -r vsochat@login.sherlock.stanford.edu:/scratch/users/vsochat/first-order-model/videos gpu-videos
Mind you that it’s up to you to figure out how to do this efficiently.
Adding Audio
Once you’ve generated the result file, you can open it up with the original file, and first add the original track to your workspace
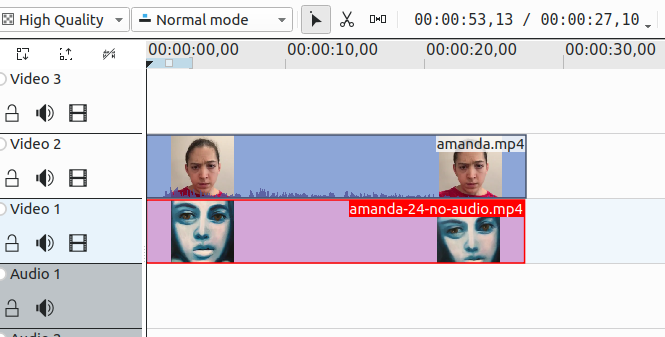
unlink the video and audio
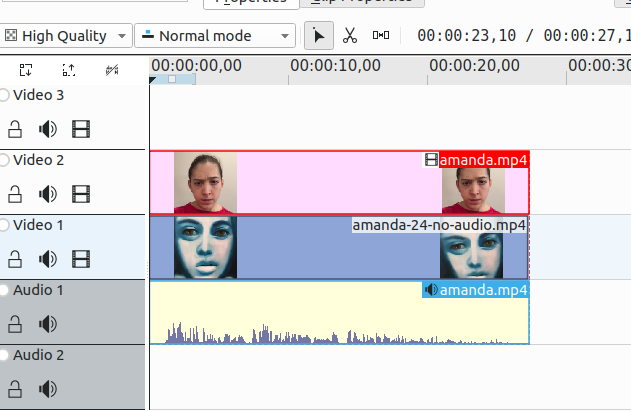
and then delete the original video. The audio is now paired with your (silent) video and should match, time wise, 1:1.
The Final Result!
Ladies and gentlemen, what I spent an entire day of my weekend doing. Behold! Mind you these are only the publicly sharable ones - the best ones have real people’s faces (and I will share with private social networks only).
Inanimate Objects
The Can Opener
Meow Cheese
Meow Flower
Angry Cheese
Angry Pepper
Baby Bumble Bee Octocat
Baby Bumble Bee Avocado
Paintings and Drawings
Person Flower
I Pained Myself
You are My Sunshine
Stuffed Flower
Hi Mom and Dad!
Sunburn
You Can’t Get to Heaven
I Painted Myself (Flower)
Lester’s Eggs
Amanda (dark)
This one is a little dark, but it’s meant to be.
Trump Growl
Knock Knock Flower
Knock Knock (2)
Knock Knock (3)
Pancakes
I have more work to do, and more to discuss, but really need to stop today! We didn’t even scratch the surface because checkpoints are provided for models with different kinds of videos (e.g., someone walking) and we can also try so many more things. This is definitely why I shouldn’t be trusted with machine learning! But no matter, I had an amazing day! If you feel a bit silly and don’t mind recording yourself and putting in a bit of work, this is a hugely fun and rewarding project. Have fun!